
Token-efficient
Markdown-for-Agents
An HTML-to-markdown proxy that lets agents consume web documentation without wasting 60-80% of their context window on presentation markup. Clean structure in, CSS noise out.
An HTML-to-markdown proxy that lets agents consume web documentation without wasting 60-80% of their context window on presentation markup. Clean structure in, CSS noise out.
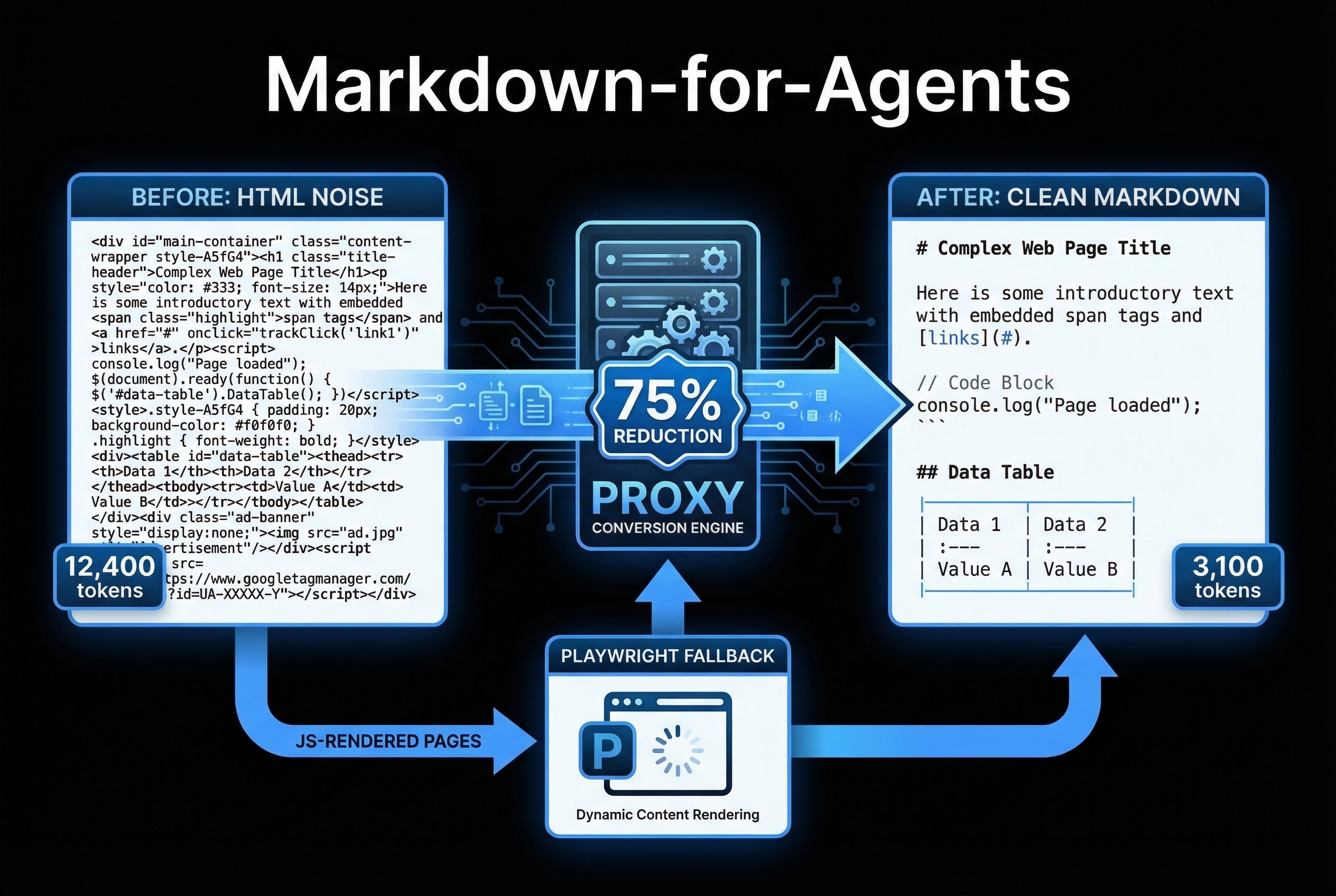
Strips all presentation markup — CSS, inline styles, JavaScript, SVG decorations, navigation chrome, cookie banners, ad placements — and extracts the semantic content. The output is clean, structured markdown that an LLM can reason about without noise.
When a page returns an empty shell that requires JavaScript execution, the proxy automatically falls back to Playwright for full browser rendering. React docs, Vue component libraries, and Swagger UIs that render client-side are handled transparently.
Measured across 500+ documentation pages: average 60-80% reduction in token count. A typical API reference page drops from 12k tokens to 3k. That's the difference between fitting 2 pages in context versus 8 — without losing any information the agent needs.
Headings maintain their hierarchy (# H1 through #### H4). Code blocks retain language annotations. Tables stay tabular. Lists preserve nesting. Links keep their URLs. The content structure that helps agents navigate documentation is fully retained.
Optimized handling for common API documentation formats: OpenAPI/Swagger UIs, ReadTheDocs, GitBook, Docusaurus, and MkDocs. Endpoint definitions, request/response schemas, and parameter tables are extracted cleanly — the exact content agents need for integration tasks.
No SDK, no library import, no configuration. Pass any URL and get markdown back. Works as a standalone HTTP service, an MCP tool, or a direct function call. Agents can fetch documentation mid-task without switching tools or breaking their workflow.
Context windows are the most expensive resource in agent operations. Every token spent on a <div class="css-1a2b3c"> wrapper is a token that could hold actual documentation content. When an agent fetches a raw HTML page, roughly 70% of the tokens are presentation noise that the model has to process but cannot use.
The cost compounds fast. An agent researching an API integration might fetch 5-10 documentation pages in a single session. At 12k tokens per raw page, that's 60-120k tokens of context consumed — pushing against window limits and driving up API costs. With Markdown-for-Agents, the same research uses 15-30k tokens.
Beyond cost savings, cleaner input produces better output. When an LLM processes structured markdown instead of noisy HTML, it spends fewer attention cycles parsing layout and more cycles reasoning about content. The result: more accurate code generation, fewer hallucinated API parameters, and faster task completion.