A Complete Autonomous Development Factory
Seven integrated domains that cover every phase from requirements to deployment — with quality gates at every handoff.
Multi-Agent Orchestration
29 specialized agents route every task through the right expertise. 5-signal classification determines complexity, and tiered quality gates ensure nothing moves forward without review.

Plugin Ecosystem
Extensible at every level. 8 lifecycle hooks intercept every tool call, every session start, every context compression. Skills, commands, and MCP integration let you customize the entire pipeline.
Agent Governance
Trust levels, data classification ceilings, audit trails, and LLM threat detection. Every agent action is logged, every permission is enforced, every decision is traceable.
Persistent Vector Memory
Agents learn from every interaction. Semantic recall surfaces institutional knowledge across sessions. Procedures, trajectories, and learnings accumulate into organizational intelligence.
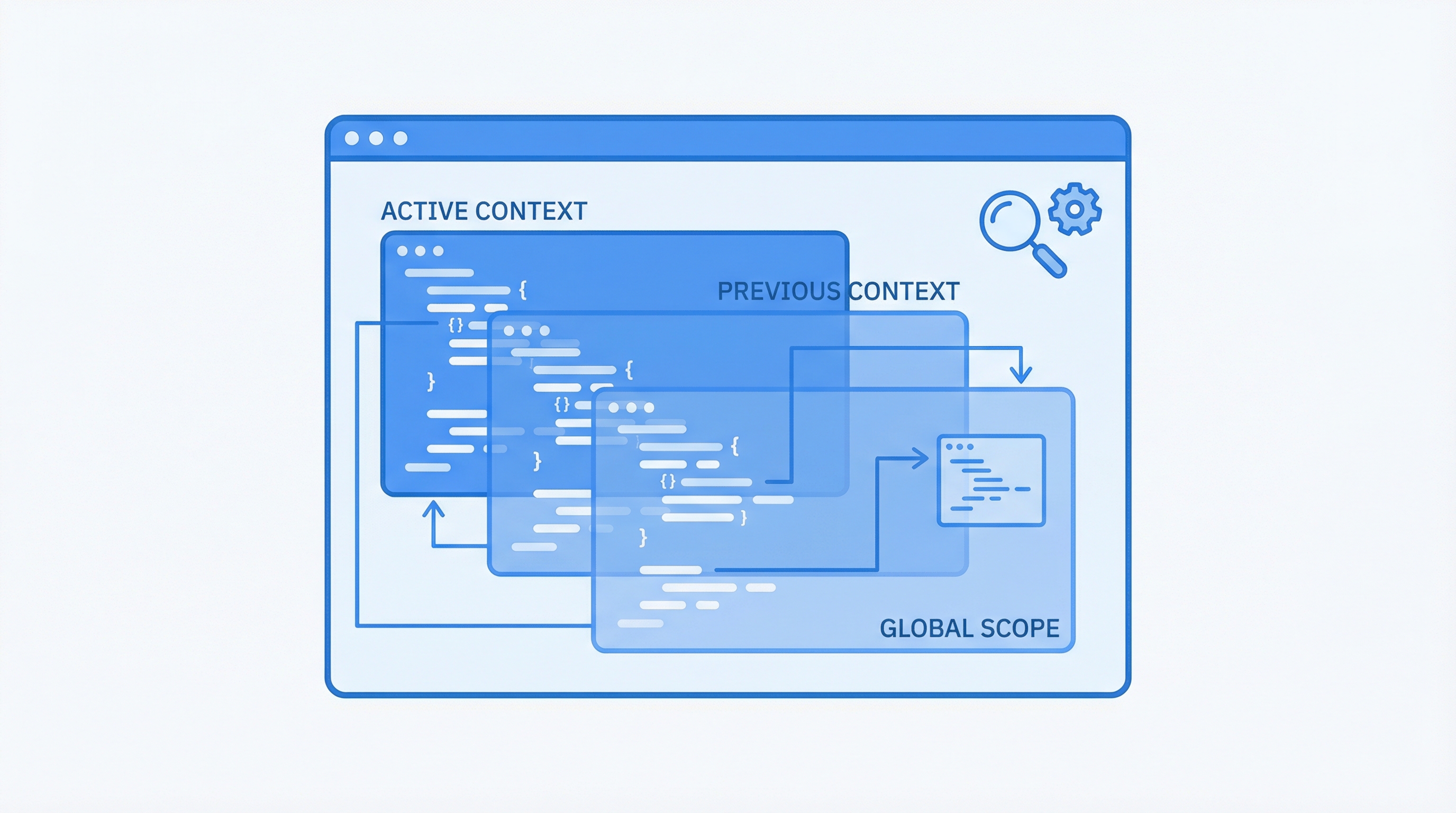
Context Management
Hierarchical context ensures agents maintain coherent behavior across sessions, projects, and teams. Auto-memory and intelligent compression prevent context loss.
Memory Dashboard
D3.js knowledge graphs, semantic search, drift detection, and collection monitoring. See what your agents know, what they've learned, and where knowledge gaps exist.

Markdown-for-Agents
Clean, token-efficient content from any URL. Agents consume documentation, APIs, and reference material without wasting context on HTML noise.